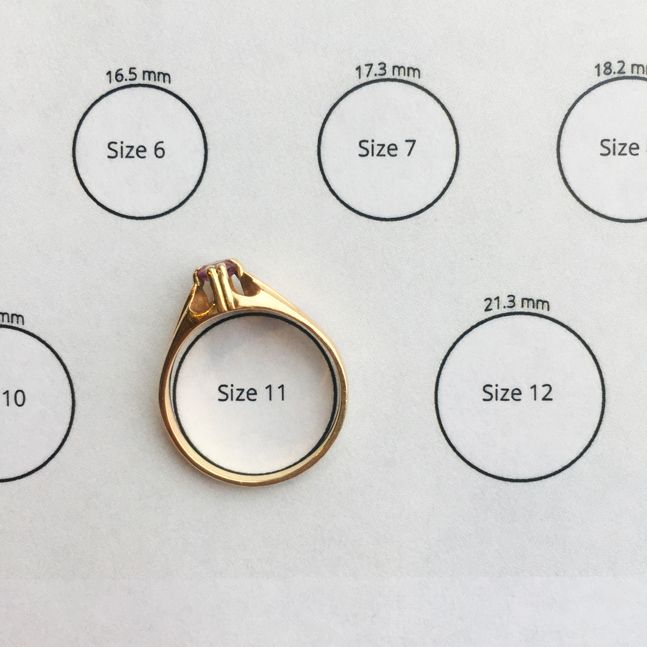
Размеры серебряных колец в Украине
РАЗНОВИДНОСТИ
РАЗМЕРОВ СЕРЕБРЯНЫХ КОЛЕЦ ПО СТРАНАМ И РЕГИОНАМ.
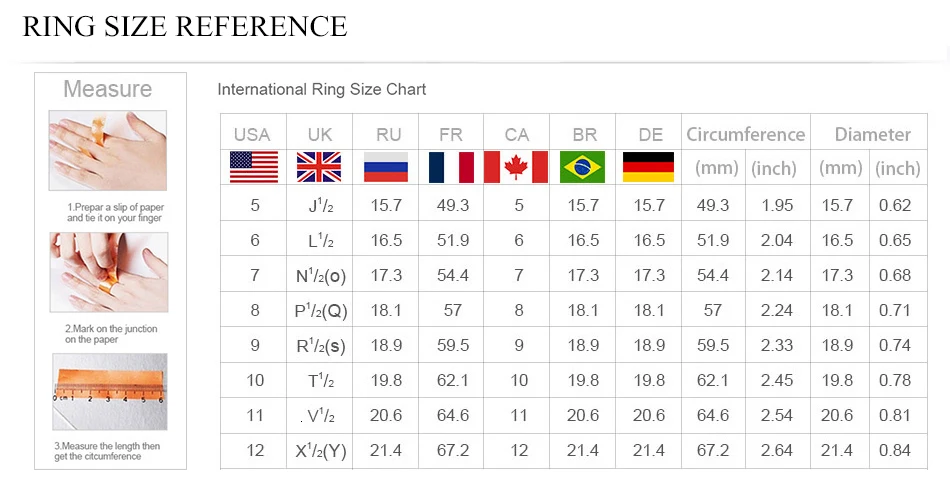
В мире существует множество стандартов регламентирующих размерность колец. Все они отличаются лишь принципами или правилами, которыми руководствуются в той или иной стране для отражения обозначения размерности.
Как узнать размер кольца ?
Как понять размер кольца ?
Как узнать свой размер кольца ?
СЕРЬГИ✨ СЕРЕБРЯНЫЕ КОЛЬЦА
ПОДВЕСКИ✨ЦЕПИ
Кольца из серебра не отличаются, по принципу определения размера, от колец, изготовленных из других материалов.
ЮВЕЛИРНЫЕ ИЗДЕЛИЯ-СЕРЕБРЯНОЕ КОЛЬЦО-РАЗМЕР
Что бы купить кольцо из серебра надо понимать, как определяется размер ювелирного изделия.
Серебро это или другой металл – мало значимо. Важно знать в какой стране приобретается серебряное кольцо!В Украине размер кольца (принцип формирования стандарта) определяется по его внутреннему диаметру!
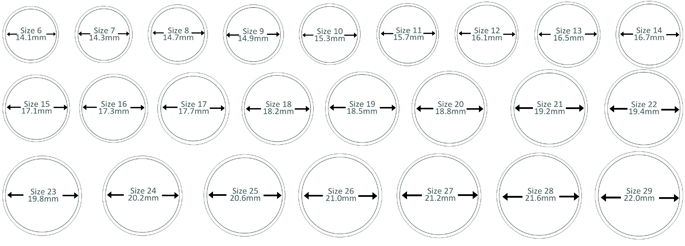
Цифра размера на бирке серебряного кольца
означает диаметр внутренней части кольца в миллиметрах.
Формула определения диаметра (D):
D = длинна окружности (Р) / делённая на число 3.14 (π)
Т.е. если длинна окружности (Р) = 44 мм то Диаметр (D) = 44 мм делить : на 3.14 (π) = результат 14 мм
14 – это и есть размер кольца на бирке.
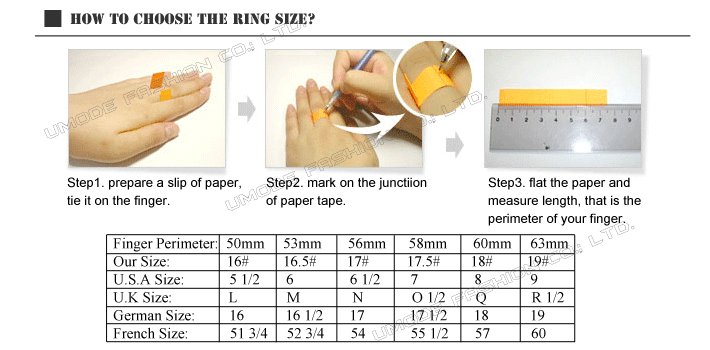
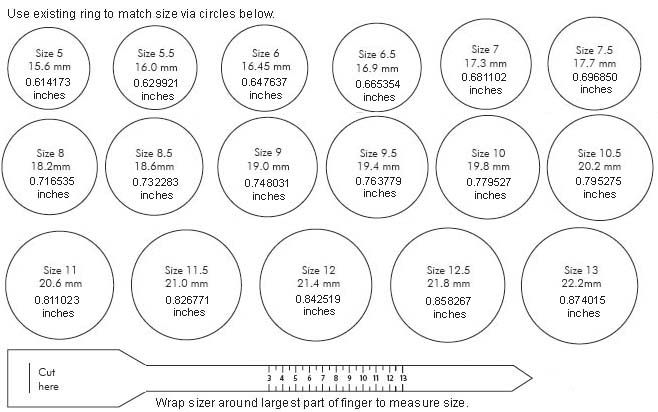
Для определения своего (индивидуального) размера серебряного кольца необходимо измерить окружность пальца (для которого предназначается купить кольцо). Например, получили длину окружности 56,5 мм. =
Некоторые бренды или интернет-магазины указывают свои размеры, не округляя
к близким по значению стандартам. Если в результате вычислений получилось число
17,9, то и размер укажут на бирке
серебряного кольца 17,9, а не 18.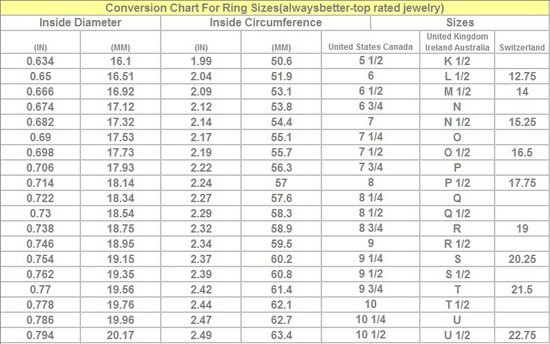
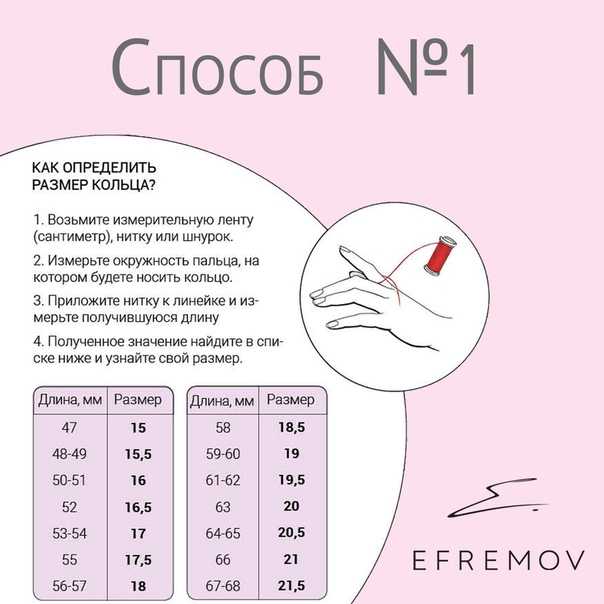
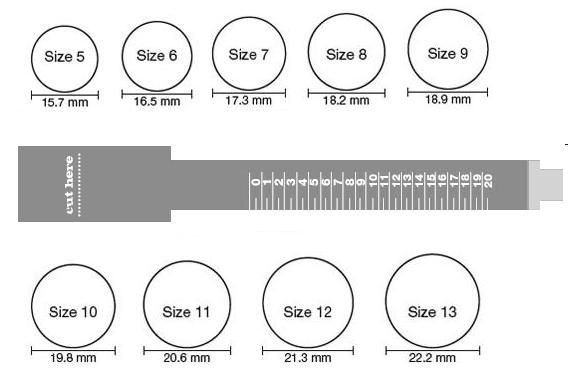
Измерить длину окружности (охват) вокруг пальца можно с помощью не растягивающейся, и не плотно прилегающей к пальцу — нити или полоски бумаги.
Оборачиваем палец, отмечаем начало и конец, разворачиваем, измеряем линейкой в миллиметрах длину от отметки до отметки. Это и будет длинна окружности (охвата) вокруг пальца (Р).
=56мм
Надо учесть размер «сустава», через который будет одеваться кольцо. Тут надо длину окружности (охват) определить, как среднее между местом ношения серебряного кольца и «косточкой сустава». В этом случае кольцо свободно оденется на палец и не потеряется при ношении.
Надо также учитывать индивидуальные особенности организма каждого человека. Например, отечность рук в течение дня и др.
Точно узнать свой размер серебряного кольца (вообще кольца) – можно воспользовавшись
шаблонами размеров. Такие шаблоны есть, практически во всех крупных ювелирных
магазинах.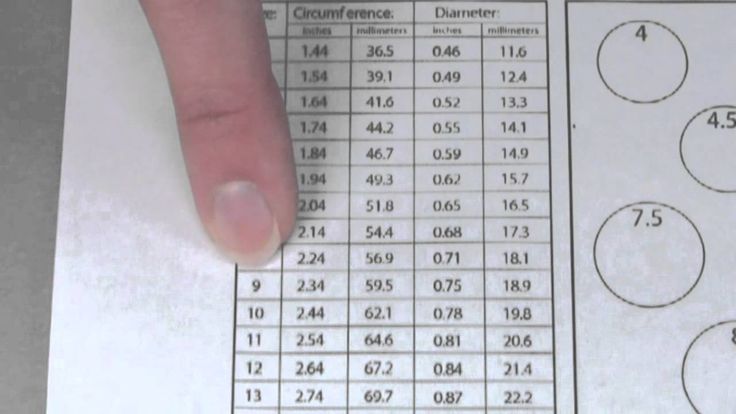
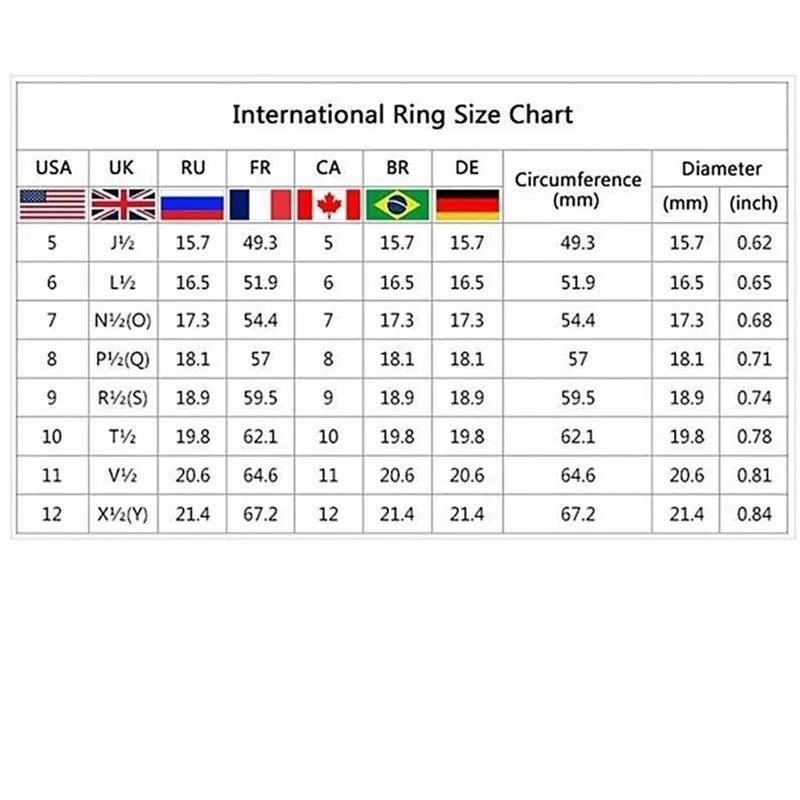
Америка
Диаметр (Украинский размер) умножаем на 1,23 (постоянный коэффициент) и — отнимаем цифру 14,3 =
Американский размер
Соответственно, имея американский размер серебряного кольца,
Например – 8 (Американский размер)
Франция
От длинны окружности, (охвата пальца или европейский стандарт) отнимают 40 мм и получают стандартный французский размер кольца!
Япония и некоторые азиатские страны.
Диаметр (
D — Украинский размер) умножаем на 3 (постоянный коэффициент) и – отнимаем цифру 38 = Японский соответственный стандарт.
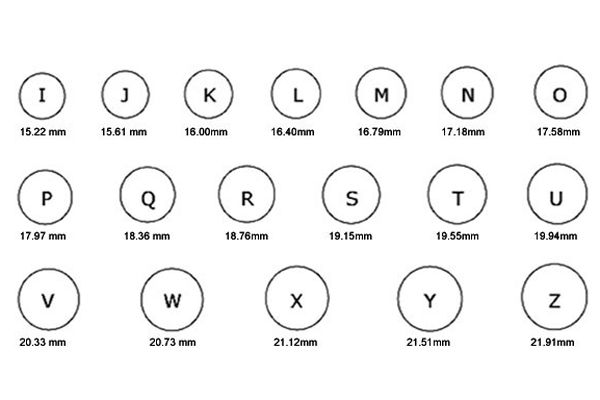
В Англии размеры ювелирных колец
обозначаются буквами, где буква например «В» – это вторая буква алфавита.
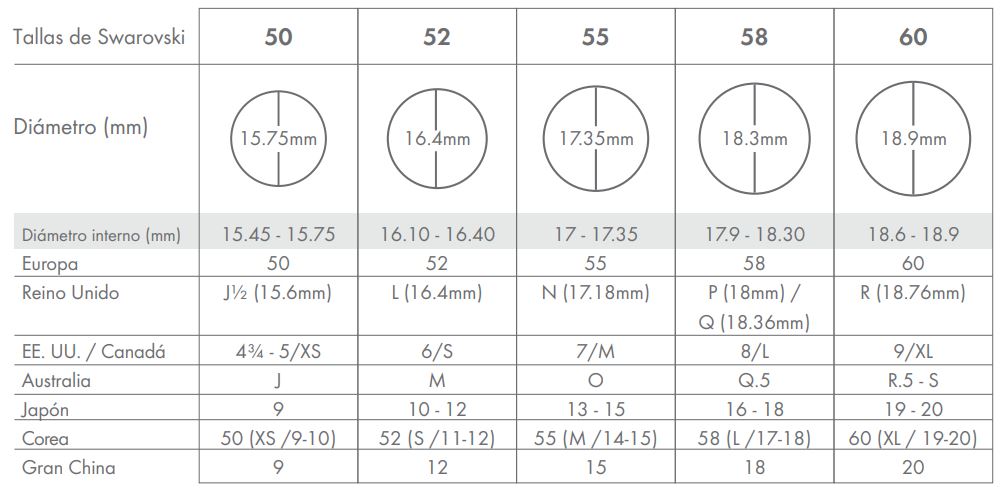
Италия, Англия, Австрия, другие европейские страны имеют свою систему и стандарты определения размеров серебряных колец или ювелирных колец вообще.
Но такие региональные стандарты встречаются все реже и реже.
Любой европейский магазин или интернет-магазин, предлагающий кольца из серебра, укажет размер равный длине окружности кольца. Это и есть
европейский стандарт размера серебряного кольца, любого другого ювелирного кольца. Такой стандарт еще носит название Венский.
Как видим процесс вычисления соответствия размеров, может занять длительное время, да и можно ошибиться в процессе сравнения цены, валюты, курса, метрических систем и т.д. Купить кольцо из серебра окажется сложно, нудно и т.д. Цена на него сложится из множества проблем.
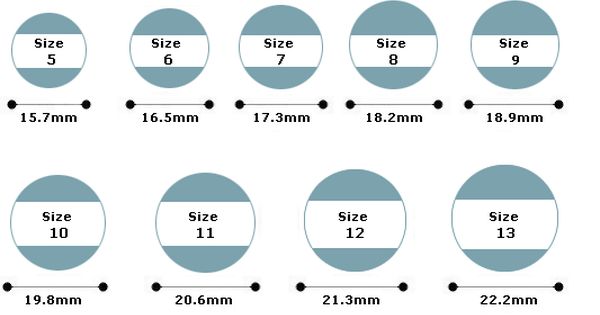
Проще воспользоваться таблицей соответствия размеров
колец.
РАЗМЕРЫ СЕРЕБРЯНЫХ КОЛЕЦ НА САЙТЕ:
☞15✦ ☞15.5✦ ☞16✦ ☞16.5✦ ☞17✦ ☞17.5✦ ☞
✨
ТОНКОЕ СЕРЕБРЯНОЕ КОЛЬЦО
ШИРОКОЕ СЕРЕБРЯНОЕ КОЛЬЦО
ПОМОЛВОЧНОЕ СЕРЕБРЯНОЕ КОЛЬЦО
ВЕЧЕРНЕЕ (КОКТЕЙЛЬНОЕ) СЕРЕБРЯНОЕ КОЛЬЦО
ПОВСЕДНЕВНОЕ СЕРЕБРЯНОЕ КОЛЬЦО
КЛАССИЧЕСКОЕ СЕРЕБРЯНОЕ КОЛЬЦО
ОБРУЧАЛЬНОЕ РОДИРОВАННОЕ СЕРЕБРЯНОЕ КОЛЬЦО
✨
Ювелирный интернет магазин серебряных украшений . Украина. Киев–2019.
Покупайте, дарите, наслаждайтесь – серебро прекрасно. Доставка по всей Украине.
✨ SRIBLODARTM ✨
Как найти проблему с производительностью ВМ на VMware ESXi / Хабр
В этой статье я расскажу, как искать иголку в стоге сена причину проблем с производительностью ВМ на ESXi. Главным способом будет то, что так не любят многие администраторы: планомерная проверка всех ресурсов на утилизацию, сатурацию и ошибки. Я приведу ключевые метрики, на которые следует обратить внимание, их краткое описание и значения, на которые можно ориентироваться, как на норму. При этом важно понимать, что разные системы имеют разные требования к производительности. Следовательно, то, что приемлемо для одной системы, для другой может являться признаком аварийного состояния.
Главным способом будет то, что так не любят многие администраторы: планомерная проверка всех ресурсов на утилизацию, сатурацию и ошибки. Я приведу ключевые метрики, на которые следует обратить внимание, их краткое описание и значения, на которые можно ориентироваться, как на норму. При этом важно понимать, что разные системы имеют разные требования к производительности. Следовательно, то, что приемлемо для одной системы, для другой может являться признаком аварийного состояния.
Кроме своих наработок, я также использовал материалы из разных англоязычных источников. По некоторым вопросам описания тянули на отдельные статьи, поэтому на них я дал ссылки.
Нашим первым шагом должна быть быстрая базовая проверка основных параметров – ее сценарий я опишу в начале статьи. Если базовая проверка не нашла причины проблем, то, скорее всего, укажет направление, в котором мы запустим расширенную проверку. В любом случае, более глубокая расширенная проверка всех доступных параметров поможет в итоге найти корень проблем. С этим обнадеживающим фактом давайте приступим. Напомню, что проверяемые параметры стоит фиксировать скриншотами.
С этим обнадеживающим фактом давайте приступим. Напомню, что проверяемые параметры стоит фиксировать скриншотами.
Выясняем симптомы проблемы
Вот краткий список ключевых вопросов, на которые нужно ответить:
1. Как проявляются проблемы производительности? Описываем словами, снимками, прикладываем графики.
2. Когда работало хорошо и когда начало работать плохо? Вспоминаем даты и время.
3. Были ли какие-то аппаратные, программные или нагрузочные изменения?
4. Охватывает ли проблема другие системы или только одну, например: ВМ, vApp, группу ВМ, кластер, группу кластеров и т. д.
Часть 1. Базовая проверка
Цель базовой проверки – быстро выяснить направление, в котором находится источник проблем производительности. Учитывайте, что графики в vSphere Client усредняют значения со временем, и лучше собирать максимум информации в любую стороннюю систему мониторинга (Prometeus, Zabbix, VMware vRealize Operation Manager и т. д.). Если такой системы нет, то воспроизводим проблему в реальном времени и наблюдаем за ней со стороны гипервизора.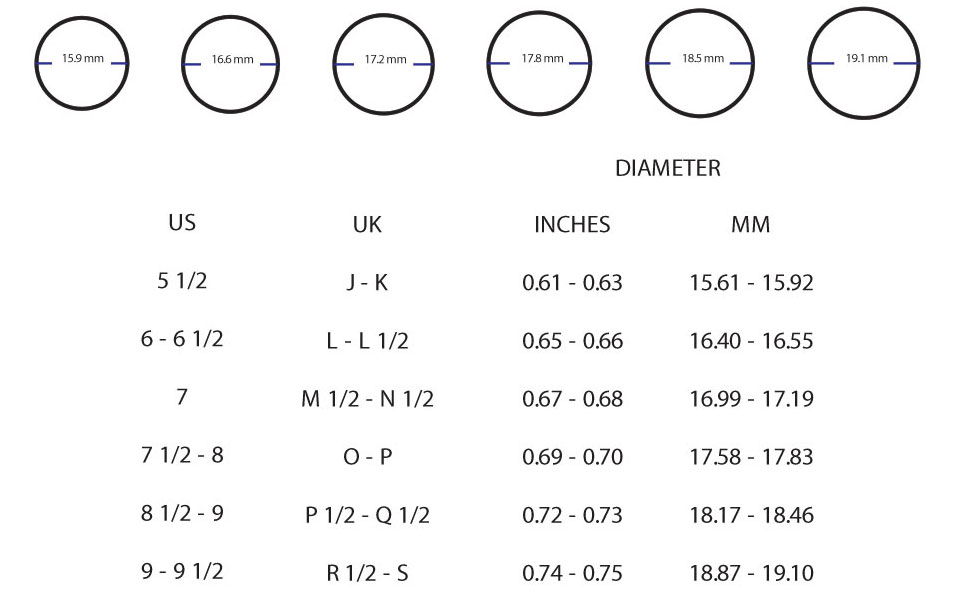 По результатам базовой проверки решаем, нужно ли дальнейшее расследование.
По результатам базовой проверки решаем, нужно ли дальнейшее расследование.
Проверяем ВМ из vSphere Client
Triggered Alarms, Tasks и Events не должны содержать событий, коррелирующих с проблемой.
CPU
Usage не должен превышать 90%.
Usage – процент активно задействованных мощностей виртуальных CPU. Это среднее значение загруженности CPU в виртуальной машине. Например, если виртуальная машина с одним виртуальным CPU работает на хосте, имеющем четыре физических CPU, и Usage виртуального CPU составляет 100%, то виртуальная машина полностью использует один физический CPU.
Usage виртуального CPU = usagemhz / кол-во виртуальных CPU x частота ядра.
Ready не должен превышать 10% на ядро.
Ready показывает время, в течение которого виртуальная машина была готова к использованию, но не могла быть запущена на физическом CPU из-за нехватки ресурсов. Ready % зависит от количества виртуальных машин на хосте и загруженности их CPU.

Memory
Ballooned должен быть равен 0.
Этот параметр указывает на объем памяти, захваченной драйвером управления памятью ВМ (vmmemctl), который установлен в гостевую ОС вместе с VMware Tools. Данный объем перераспределяется от ВМ к гипервизору в условиях её нехватки. То же самое происходит, когда неверно выставлен Memory Limit на ВМ или ресурсный пул – это тоже ухудшает производительность ВМ.
Swapped должен быть равен 0.
Это текущий объем гостевой физической памяти, которую VMkernel выгрузил в файл подкачки ВМ. Выгруженная память остается на диске до тех пор, пока она не понадобится ВМ, либо пока не будет запущен принудительный механизм unswap. Подробнее расписано тут: https://www.yellow-bricks.com/2016/06/02/memory-pages-swapped-can-unswap/
Virtual Disk
Нормально, если отсутствуют мгновенные снимки старше 24 часов.
Highest latency не должен превышать приемлемых для приложения значений.
Это наибольшее значение задержки среди всех дисков, используемых ВМ. Измеряет время, необходимое для обработки команды SCSI, которое гостевая ОС предоставила виртуальной машине. Задержка ядра – это время, которое требуется VMkernel для обработки запроса ввода/вывода. Задержка устройства – это время, которое требуется оборудованию для обработки запроса.
Есть прямая зависимость от размера блока ввода/вывода (Write request size и Read request size) с временем задержки, за которое этот блок будет обработан подсистемой хранения.
Write request size и Read request size не должны коррелировать с Highest latency.
Важным нюансом этой метрики является то, что vSphere не отображает размеры блока более 512 КБ: вы увидите рост задержек вследствие роста размера блока выше 512 КБ, но при этом не будете видеть рост размера самого блока. Увидеть его можно только через утилиту хоста ESXi vscsiStats.
Подробнее о vscsiStats здесь: https://communities.vmware.com/t5/Storage-Performance/Using-vscsiStats-for-Storage-Performance-Analysis/ta-p/2796805
Здесь можно превратить вывод команды в гистограмму: https://www.
virten.net/vmware/vscsistats-grapher/Average commands issued per second не должен превышать IOPS Limit.
Commands aborted и Bus resets должны равняться 0.
Network
Usage не должен достигать предела (vmnic хоста, политик коммутирующего оборудования или маршрутизатора).
Этот параметр отображает объем данных, переданных и полученных всеми виртуальными сетевыми картами, подключенными к виртуальной машине.
Receive packets dropped и Transmit packets dropped должен равняться 0.
Packets received и Packets transmitted не должны содержать скачков, коррелирующих с проблемой в разбивке по типам Broadcast, Unicast и Multicast.
 virten.net/vmware/vscsistats-grapher/
virten.net/vmware/vscsistats-grapher/Проверяем хост из vSphere Client
Triggered Alarms, Tasks и Events не должны содержать событий, коррелирующих с проблемой.
CPU
Usage по всему хосту не должен превышать 80%.
Ready не должен превышать 10% на ядро (как перевести из summation в проценты подробно читайте тут: https://kb.
vmware.com/s/article/2002181).
Memory
Balloned должен равняться 0.
Это сумма значений vmmemctl для всех включенных ВМ и служб vSphere на хосте. Если целевой размер balloon (дословно переводится как «шар») больше, чем текущий, VMkernel «раздувает» balloon внутри ВМ, в результате чего освобождается больше памяти хоста. Если целевой размер balloon меньше, чем текущий, VMkernel «сдувает» balloon, что позволяет процессам внутри ВМ при необходимости использовать больше памяти. Подробнее про ballooning тут: https://docs.vmware.com/en/VMware-vSphere/8.0/vsphere-resource-management/GUID-2B1086F3-B3F5-426C-9162-3C3CDD23A5DF.html
Swap consumed должен быть равен 0.
Это объем памяти, которая используется для подкачки всех включенных ВМ и служб vSphere на хосте.
Page-fault latency должно равняться 0.
Это время ожидания виртуальной машиной доступа к сжатой памяти или файлу подкачки.
4. Storage adapter
Write rate и Read rate не должны превышать пропускную способность vmhba, коммутирующего оборудования до хранилища или пропускной способности хранилища.
Write latency и Read latency должны примерно равняться по всем активным vmhba.
Если какая-то из vmhba сильно выбивается по задержкам или нагрузке, то следует удостовериться, что политика мультипасинга выставлена корректно. Подробнее о политиках тут: https://kb.vmware.com/s/article/1011340. Большинство современных хранилищ позволяют применять политику Round Robin. После проверки политики стоит обратить внимание на качество соединения.
5. Network:
Usage не должен превышать пределов vmnic.
Это суммарный объем данных, которые передают и получают все физические сетевые карты, подключенные к хосту.
Receive packets dropped и Transmit packets dropped должны равняться 0.
Packets received и Packets transmitted не должны содержать скачков, коррелирующих с проблемой в разбивке по типам Broadcast, Unicast и Multicast.
 vmware.com/s/article/2002181).
vmware.com/s/article/2002181).Если результаты базовой проверки не указали на главную причину проблем с производительностью, делаем расширенную проверку.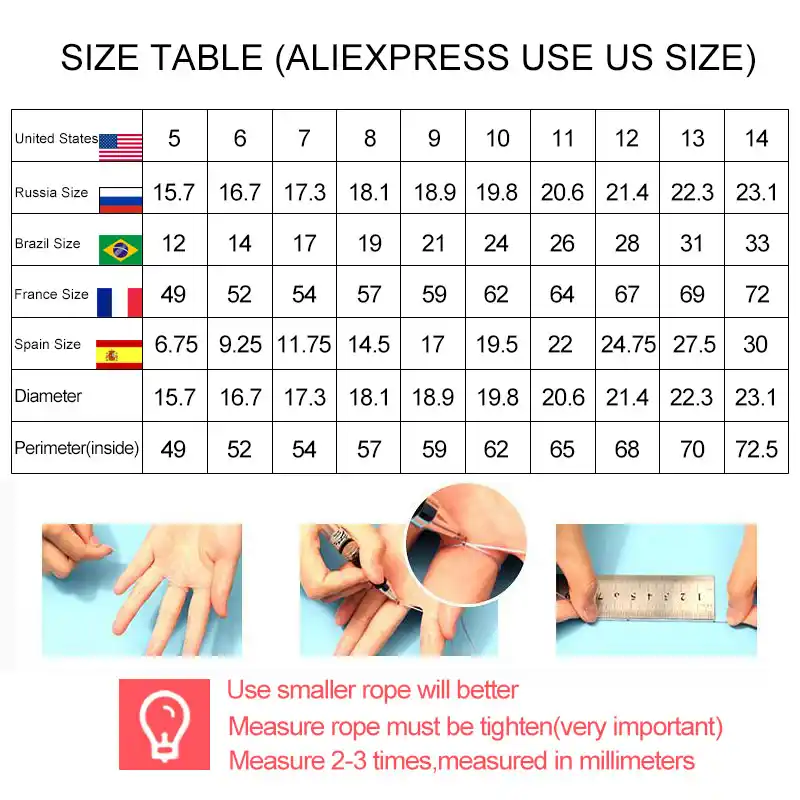
Проверяем ВМ и хост
Здесь большая часть метрик берется из утилиты хоста ESXi esxtop. Очень кстати вывод esxtop можно записывать в csv-файл. Формат csv позволяет открыть его, к примеру, в PerfMon на Windows и проанализировать не только мгновенные значения, но и их изменение во времени.
Запись одной тысячи точек с шагом раз в две секунды можно выполнить так:
esxtop -a -b -d 2 -n 1000 > esxtop-output.csv
Должны отсутствовать ошибки в vmware.log ВМ, vmkernel.log хоста, в журнале IPMI хоста и во внешних системах журналирования по объектам, релевантным проблеме.
CPU в esxtop (клавиша ‘c’)
CPU load average не должен превышать 1.
Это среднее арифметическое значение загрузки CPU за 1 минуту, 5 минут и 15 минут, основанное на 6-секундных выборках.
%USED не должен превышать 90 на ядро.
Это процент физического процессорного времени, приходящийся на world. В эту величину входит метрика %RUN, обозначающая процент времени, когда world вычислялся на физическом CPU.
Дополнительно сюда засчитывается %SYS, обозначающая процент времени, при котором VMkernel обрабатывал прерывания и выполнял иные системные действия для данного world. Метрика же %OVRLP вычитается из данной и отражает процент времени, которое world провел в очереди на выполнение, ожидая завершения системных действий в отношении других world.%USED = %RUN + %SYS — %OVRLP.
%RDY не должен превышать 10.
Это процент времени, в течение которого world был готов к запуску.
Поясню: world, который стоит в очереди, ожидает, пока планировщик разрешит ему запуск на физическом CPU. %RDY – процент от этого времени, поэтому он всегда меньше 100%.
Если в настройках ресурсов ВМ установлен CPU Limit, то планировщик не станет размещать ВМ на физическом CPU, когда она израсходует выделенный ей ресурс CPU. Это может произойти даже при наличии большого количества свободных тактов CPU. Время, в течение которого планировщик намеренно удерживает ВМ, отображается в параметре %MLMTD, который мы опишем дальше.
Обратите внимание, что параметр %RDY включает в себя %MLMTD. Для определения задержки процессора мы будем использовать формулу: %RDY – %MLMTD. Поэтому, если показатель %RDY – %MLMTD высокий, например больше 10%, вы можете столкнуться с проблемой нехватки мощностей CPU.Рекомендуемый порог зависит от обстоятельств. Для пробы можно начать с 10%. Если скорость работы приложения в ВМ в порядке, то оставьте порог как есть. В противном случае – снизьте порог.
Закономерный вопрос: а что составляет 100% времени?
World может находиться в разных состояниях: он запланирован к запуску, готов к запуску, но не запланирован, или не готов к запуску, то есть ожидает какое-либо событие.
100% = %RUN + %RDY + %CSTP + %WAIT.
%CSTP не должен превышать 3.
Это процент времени, в течение которого world находится в состоянии co-schedule. Состояние co-schedule применимо только для многопроцессорных виртуальных машин. Планировщик CPU ESXi намеренно переводит виртуальный CPU в это состояние, если этот виртуальный CPU опережает в вычислениях другие виртуальные CPU данной ВМ.
Высокий показатель %CSTP означает, что ВМ неравномерно использует виртуальные CPU. Приложение использует CPU с высоким %CSTP внутри ВМ гораздо чаще, чем остальные её CPU.
%MLMTD должен равняться 0.
Это процент времени, в течение которого world был готов к запуску, но не запущен планировщиком из-за настроек CPU Limit.
Обратите внимание, что параметр %MLMTD уже учтен в расчете %RDY. Показатель %MLMTD высок, когда ВМ не может быть запущена из-за настройки CPU Limit. Если вы хотите повысить производительность этой ВМ, то увеличьте этот лимит. В целом, использование CPU Limit не рекомендуется.
%SWPWT должен равняться 0.
Это процент времени, в течение которого world ожидает, пока VMkernel завершит подкачку памяти. Время %SWPWT (ожидание подкачки) включено в %WAIT.
Memory в esxtop (клавиша ‘m’)
Memory хоста в состоянии High. Про memory state подробно написано здесь: https://www.yellow-bricks.com/2015/03/02/what-happens-at-which-vsphere-memory-state/
MCTLSZ должен равняться 0.
Это объем гостевой физической памяти, перераспределенной balloon-драйвером.
Высокий показатель MCTLSZ означает, что много гостевой физической памяти этой виртуальной машины «украдено», чтобы уменьшить нагрузку на память хоста.
Как тогда узнать, что виртуальная машина работает в режиме ballooning? Если показатель MCTLSZ изменяется, balloon-драйвер активно освобождает память хоста, раздувая «шар памяти» в ВМ. Скорость ballooning в краткосрочной перспективе можно оценить по изменению MCTLSZ в какую-либо сторону.
SWCUR должен равняться 0.
Это общее количество мегабайт подкачки, которые используются в файле vswp ВМ или в системном файле подкачки, а также миграционном файле подкачки. ВМ в состоянии vMotion использует миграционный файл подкачки для удержания выгруженной памяти на целевом узле, если целевому узлу не хватает памяти.
Для ВМ это текущий объем гостевой физической памяти, выгруженной в зарезервированное хранилище. Обратите внимание, что эта статистика относится к своппингу VMkernel, а не к своппингу гостевой ОС внутри ВМ.
Высокий показатель SWCUR у ВМ означает, что гостевая физическая память ВМ находится не в оперативной памяти, а на диске.
N%L должен быть больше 80.
Это процент объема виртуальной памяти ВМ, который находится в локальной для её виртуальных CPU NUMA Node. Низкий процент N%L означает, что, с высокой вероятностью, какие-то запросы виртуальных процессоров ВМ используют данные оперативной памяти ВМ через межпроцессорное соединение.
Подробнее об этом можно почитать в цикле статей от Frank Denneman: https://frankdenneman.nl/2016/07/06/introduction-2016-numa-deep-dive-series/.
Disk ВМ в esxtop (клавиша ‘v’)
LAT/rd и LAT/wr не должны превышать приемлемых для приложения значений.
CMDS/s не должен достигать IOPS Limit.
MBREAD/s + MBWRTN/s не должен достигать пределов vmhba.
Disk Adapter в esxtop (клавиша ‘d’)
QAVG/cmd должно быть около 0 и не превышать KAVG/cmd.
Это среднее время ожидания в очереди.
QAVG должен входить в KAVG. Но при проблемах с физическим устройством или соединительными линиями QAVG может превышать KAVG. Если показатель QAVG высокий, то следует обратить внимание на глубину очередей на каждом уровне стека хранения.
GAVG/cmd, KAVG/cmd и DAVG/cmd не должны превышать приемлемые значения для данного хранилища данных.
GAVG – это круговая задержка для всех запросов ввода/вывода, которые гостевая система отправляет на виртуальное устройство хранения. Параметр GAVG = KAVG + DAVG.
KAVG – этот параметр отслеживает задержки, связанные с работой VMkernel.
Значение KAVG должно быть намного меньше значения DAVG и близко к нулю. Когда в ESXi много очередей, KAVG может быть таким же высоким или даже выше, чем DAVG. Если это произошло, проверьте статистику очередей и лимиты политики хранения или виртуального диска.
DAVG – это задержка, наблюдаемая на уровне драйвера устройства. Она включает в себя время приема-передачи между HBA и хранилищем.
DAVG – хороший индикатор производительности хранилища. Если есть подозрения, что задержки ввода/вывода являются причиной проблем с производительностью, то следует проверить DAVG. Сравните задержки ввода/вывода с соответствующими данными из массива. Если они сходятся, проверьте массив на предмет неправильной конфигурации или неисправностей. Если нет, то сравните DAVG с соответствующими данными из точек между массивом и сервером ESXi, например, FC-коммутаторов. Если эти промежуточные данные также совпадают со значениями DAVG, вероятно, приложению не хватает ресурсов для корректной работы в этом хранилище. В таких случаях может помочь добавление накопителей или изменение уровня RAID.
MBREAD/s + MBWRTN/s не должна достигать пределов vmhba.
FCMDS/s, ABRTS/s, RESETS/s должны равняться 0.
FCMDS/s – это количество команд в секунду, завершившихся ошибкой. Может указывать на проблемы с контроллером хранения, состоянием соединения до хранилища или непосредственно с хранилищем.
ABRTS/s – это количество прерванных команд в секунду. Параметр может указывать на то, что система хранения данных не удовлетворяет требованиям гостевой ОС. Гостевая система прерывает обработку команды, если хранилище не отвечает в течение приемлемого времени (может быть настроено в гостевой ОС, в том числе и в результате установки VMware Tools). Кроме того, гостевая ОС может прервать все команды, выполняемые на ее виртуальном SCSI-адаптере.
RESETS/s – это количество сброшенных команд в секунду. Указывает на число отброшенных команд в результате сброса состояния адаптера. Сброс может быть вызван драйвером как реакция на какие-либо события в сети хранения данных.
FC
Вывод команды esxcli storage san fc stats get не должен содержать ошибок.
Мониторинг портов сети хранения данных не должен содержать ошибок.
Disk device в esxtop (клавиша ‘u’)
QAVG/cmd должно быть около 0 и не превышать KAVG/cmd.
KAVG/cmd должно быть около 0.
DAVG/cmd, GAVG/cmd не должны превышать приемлемых для приложения значений.
DQLEN должно быть более 32 (кроме устройств USB и CDROM).
Глубина очереди (queue depth) – одна из ключевых характеристик подсистемы ввода/вывода, особенно в виртуализации, где требуется высокий параллелизм операций. Глубина очереди определяет число команд ввода/вывода, которые подсистема может осуществлять одновременно. На глубину очереди влияют протоколы, аппаратные возможности устройств, прошивки и драйверы.
Регулируется, как минимум, в следующих местах:
в драйвере HBA глобально на хост: https://kb.vmware.com/s/article/1267
на каждом LUN есть два параметра: https://kb.vmware.com/s/article/1268
Device Max Queue Depth наследуется от Queue Depth драйвера HBA (предыдущий шаг). Однако может быть занижено такими технологиями, как SIOCv1 (включается в vSphere Client на Datastore) и Adaptive Queue Depth (подробнее тут: https://kb.
vmware.com/s/article/1008113), которая включается расширенными настройками QFullSampleSize и QFullThreshold.No of outstanding IOs with competing worlds (DSNRO) по умолчанию равняется 32. Это глубина очереди к LUN, если с ним одновременно работают более одной ВМ.
на контроллере и диске ВМ: https://kb.vmware.com/s/article/2053145.
Важно: если параллелизм операций с хостов ESXi превысит допустимый параллелизм нижележащих HBA, SAN или СХД, то есть совокупная глубина очереди выполняемых в настоящий момент операций ВМ превысит глубину очереди инфраструктуры, то хост будет получать SCSI-примитивы QFULL или BUSY, и в журнале vmkernel.log будут регистрироваться такие события:
H:0x0 D:0x28 P:0x0 Valid sense data: 0x## 0x## 0x##
H:0x0 D:0x08 P:0x0 Valid sense data: 0x## 0x## 0x##
H:0x0 D:0x8 P:0x0 Valid sense data: 0x## 0x## 0x##
QUED должно равняться 0.
Это количество команд VMkernel, которые находятся в очереди. Статистика применима только к world и LUN.
Большое количество команд в очереди может быть признаком того, что система хранения перегружена. Постоянно высокое значение счетчика QUED сигнализирует об узком месте (bottleneck, дословно – «бутылочное горлышко») в системе хранения, которое в некоторых случаях можно устранить, увеличив глубину очереди. После увеличения глубины очереди проверьте, что LOAD меньше 1. Это должно увеличить количество обработанных команд в секунду и повысить производительность.
%USD не должно превышать 60.
Это процент глубины очереди, используемой активными командами VMkernel. Эта статистика применима только к world и LUN.
%USD = ACTV / QLEN * 100%.
Чтобы рассчитать статистику по world, в качестве знаменателя используйте WQLEN. Для статистики LUN (устройства) в качестве знаменателя используйте LQLEN.
%USD показывает, сколько доступных слотов очереди команд задействованы.
Высокие значения говорят о возможности образования очередей. Тогда вам потребуется настроить глубину очередей для HBA, если QUED также постоянно больше 1. Размеры очередей можно настроить в нескольких местах на пути ввода/вывода. Это помогает смягчить проблемы с производительностью, вызванные большими задержками.FCMDS/s, ABRTS/s, RESETS/s должны равняться 0.
ATSF должен быть значительно меньше ATS.
Примитив VAAI Atomic Test and Set позволяет ускорить ряд операций с подсистемой хранения. Ниже приведены две статьи, подробно объясняющие каждую операцию. Множество неудавшихся операций ATS могут стать причиной проблем в работе подсистемы хранения.
Про ATS heartbeat: https://kb.vmware.com/s/article/2113956.
Про ATS lock: https://kb.vmware.com/s/article/2146451.
Политика мультипасинга должна быть рекомендована вендором СХД.
No of outstanding IOs with competing worlds (DSNRO) должно равняться Queue Depth.
Network в esxtop (клавиша ‘n’)
MbTX/s, MbRX/s не должны превышать vmnic.
Это мегабиты, передаваемые (MbTX) или принимаемые (MbRX) в секунду.
В зависимости от рабочей нагрузки MbRX/s может не совпадать с PKTRX/s, потому что размер пакетов может быть разным. Средний размер пакета можно рассчитать по формуле: средний размер пакета = MbRX/s / PKTRX/s. Увеличение размера пакетов может повысить эффективность обработки пакетов процессором. Однако потенциально это также может увеличить задержку.
%DRPTX, %DRPRX должны равняться 0.
%DRPTX – это процент потерянных исходящих пакетов.
%DRPTX = потерянные исходящие пакеты / (успешно отправленные исходящие пакеты + потерянные исходящие пакеты).
Высокое значение %DRPTX обычно указывает на проблемы с отправкой данных. Проверьте, полностью ли используются возможности физических сетевых карт. Возможно, нужно заменить сетевые карты на карты с лучшей производительностью. Или вы можете подключить еще несколько сетевых карт и настроить политику балансировки нагрузки, чтобы равномерно распределить нагрузку по всем картам.
%DRPRX – это процент потерянных входящих пакетов. Вычисляется по формуле: %DRPRX = потерянные входящие пакеты / (успешные принятые входящие пакеты + потерянные входящие пакеты).
Высокое значение %DRPRX обычно указывает на проблемы с приемом входящего трафика. Стоит выделить больше ресурсов CPU для затронутой ВМ или увеличить размер ring buffer.
Network:
Вывод команды
esxcli network nic stats get -n vmnicXне должен содержать ошибок.Статистика релевантных портов vsish не должна содержать ошибок и дропов.
Бывает так, что ВМ испытывает резкие скачки входящего трафика, способные переполнить Rx Ring Buffers. Расследовать такие ситуации можно, выяснив PORT-ID сетевой карточки ВМ через раздел network утилиты esxtop или командой
esxcli network vm list-> посмотреть World ID нужной ВМ ->esxcli network vm port list -w <World ID>.Затем в vsish:
cd/net/portsets/<vSwitch-NAME>/ports/<PORT-ID>/cat statspacket stats {pktsTx:823080899pktsTxMulticast:18571pktsTxBroadcast:1908pktsRx:961804917pktsRxMulticast:48602pktsRxBroadcast:1947286droppedTx:0droppedRx:27314}Ненулевое значение droppedRx может означать превышение Rx Ring Buffers.
Расследуем дальше:cd /net/portsets/vSwitch0/ports/<PORT-ID>/vmxnet3cat rxSummarystats of a vmxnet3 vNICrx queue {...1st ring size:10242nd ring size:64# of times the 1st ring is full:349# of times the 2nd ring is full:0...}Здесь мы видим размеры ring buffers и сколько раз они были переполнены. Ненулевое значение – хороший повод увеличить ring size. Там же есть директория rxqueues, в которой может быть одна или более поддиректорий. Если включена NetQueue или RSS, то в данных директориях можно посмотреть статистику каждой очереди по отдельности.
Вывод команды arp-scan подсети не должен содержать дубликатов IP и MAC-адресов.
Запись трафика в момент воспроизведения проблемы не должна содержать аномалий. Об этом подробнее тут: https://docs.
vmware.com/en/VMware-vSphere/8.0/vsphere-networking/GUID-C1CEBDDF-1E6E-42A8-A026-0C067DD16AE7.html.***
В этой статье был приведен список ключевых точек для исследования при поиске проблем с производительностью ВМ и их краткое описание. Если требуется более глубокое погружение в материал, то рекомендую обратиться к циклу наших прошлых статей по данной теме:
Часть 1. CPU.
Часть 2. Memory
Часть 3. Storage
На этом я завершаю описание сценария поиска проблем с производительностью ВМ на ESXi. Буду рад обсудить нюансы и ответить на вопросы.
 Дополнительно сюда засчитывается %SYS, обозначающая процент времени, при котором VMkernel обрабатывал прерывания и выполнял иные системные действия для данного world. Метрика же %OVRLP вычитается из данной и отражает процент времени, которое world провел в очереди на выполнение, ожидая завершения системных действий в отношении других world.
Дополнительно сюда засчитывается %SYS, обозначающая процент времени, при котором VMkernel обрабатывал прерывания и выполнял иные системные действия для данного world. Метрика же %OVRLP вычитается из данной и отражает процент времени, которое world провел в очереди на выполнение, ожидая завершения системных действий в отношении других world.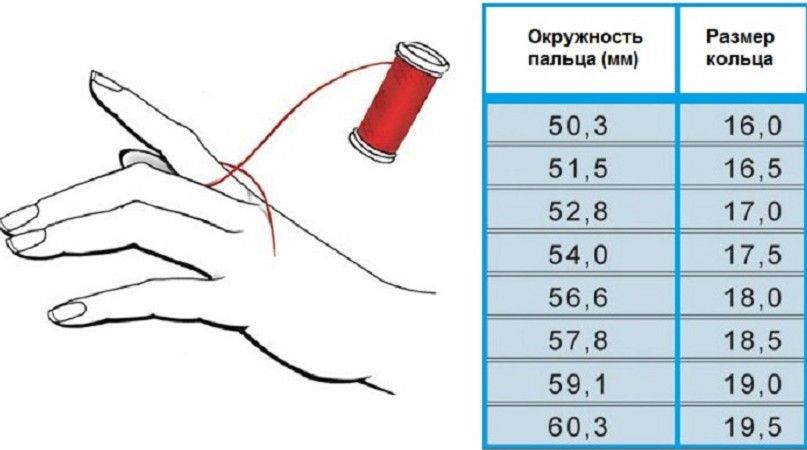 Обратите внимание, что параметр %RDY включает в себя %MLMTD. Для определения задержки процессора мы будем использовать формулу: %RDY – %MLMTD. Поэтому, если показатель %RDY – %MLMTD высокий, например больше 10%, вы можете столкнуться с проблемой нехватки мощностей CPU.
Обратите внимание, что параметр %RDY включает в себя %MLMTD. Для определения задержки процессора мы будем использовать формулу: %RDY – %MLMTD. Поэтому, если показатель %RDY – %MLMTD высокий, например больше 10%, вы можете столкнуться с проблемой нехватки мощностей CPU.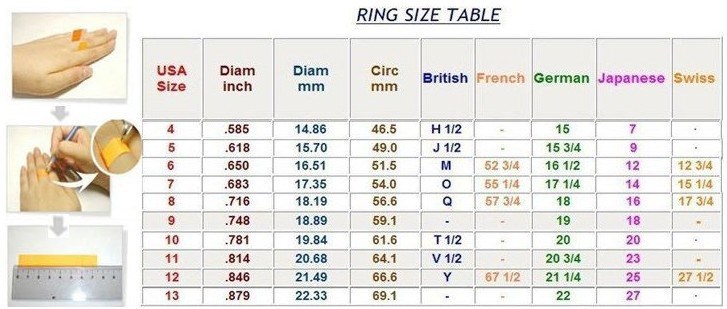


 vmware.com/s/article/1008113), которая включается расширенными настройками QFullSampleSize и QFullThreshold.
vmware.com/s/article/1008113), которая включается расширенными настройками QFullSampleSize и QFullThreshold.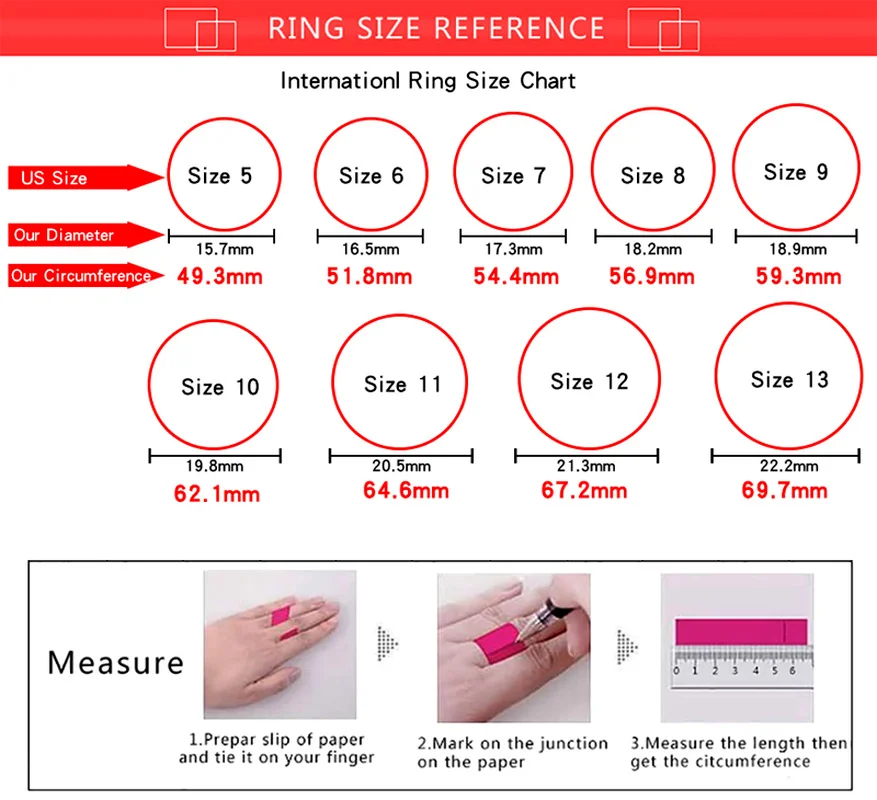
 Высокие значения говорят о возможности образования очередей. Тогда вам потребуется настроить глубину очередей для HBA, если QUED также постоянно больше 1. Размеры очередей можно настроить в нескольких местах на пути ввода/вывода. Это помогает смягчить проблемы с производительностью, вызванные большими задержками.
Высокие значения говорят о возможности образования очередей. Тогда вам потребуется настроить глубину очередей для HBA, если QUED также постоянно больше 1. Размеры очередей можно настроить в нескольких местах на пути ввода/вывода. Это помогает смягчить проблемы с производительностью, вызванные большими задержками.

 Расследуем дальше:
Расследуем дальше: vmware.com/en/VMware-vSphere/8.0/vsphere-networking/GUID-C1CEBDDF-1E6E-42A8-A026-0C067DD16AE7.html.
vmware.com/en/VMware-vSphere/8.0/vsphere-networking/GUID-C1CEBDDF-1E6E-42A8-A026-0C067DD16AE7.html.Международная таблица размеров колец
|